I needed to reinstall ERPNext because on the first installation, domain list appeared empty, only allowing me to configure the system but with no module available.
Now I reinstalled ERPNext successfully and connected to the URL. The setup wizzard appeared, then I fill all information. At this time, system allowed me to select domains, what is ok.
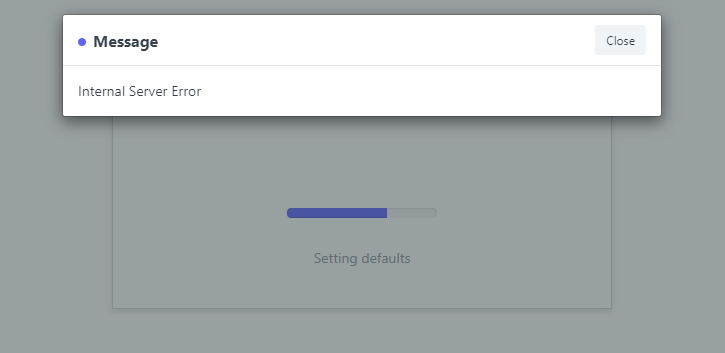
However, when completed the wizard, an Internal Server error message is shown.
I think you can’t setup erpnext if you had already finished the wizard before. You could try the bench command bellow, and then, try to run the wizard again.
Just be aware that all your DB data will be wiped out as any other customizations that you had done to this site.
Always localhost is added automatically by any system to hosts file. During my 30 years of experience in computers, I have never had the need to add localhost to hosts file, neither in Linux nor Windows machines.
Definetely, this issue is caused by another problem. The fact is that I don’t know really how ERPNext works internally and why it is needed other elements such as redis and socket io servers.
The problem is communication between application running on port 8080 when communicating to port 9000 where socket io is listening.
However, that communication occurs several times during the wizard. Only at the end it fails.
I hope some guy that really knows ERPNext could give me some hand to detect the problem. Maybe some other log shows another cause.
take down firewalls and see what happens; if it works, it’s a firewall config.
try a different browser; all of the references are to ‘http://localhost’/‘http://::site::’, but your POST error from chrome is referring to https://::site::- if you are using an extension like ‘https everywhere’ or similar and your erp site isn’t set up yet for ssl, it could be throwing an error.
take a look at how the site is configured vs how you are connecting to it to do the initial setup; your errors are… full-spectrum. You have references to localhost, 127.0.0.1, port 8000, port 8080, 9000; right alongside domains, hostnames, web addresses, and remote server ips. If you’re local- configure as local (nginx not setup; ports 8000, 8080, 9000); if you’re remote- configure as remote (nginx setup; ports 80, 443).
edit- after going back and looking at your post- it seems like the issue is that you are installing remotely and then trying to run setup on ‘local’ port defaults. When you get to the ‘specify domain’ section, and give it the basic info, it kicks into ‘remote’ mode, activates nginx (which blocks the ‘local’ ports and routes everything via 80/443), and whatever else settings changes the ‘specify domain’ section manages.
basically, yeah, I’m thinking it goes back to suggestion 3. if the machine is local, configure as local (skip domain until initial setup is successful). if the machine is remote, install via ssh cli, then configure via ssh cli (command line/frappe-bench) the domain/hostname/etc. Either way- make sure you aren’t changing the site connection settings via the site. that’s like trying to change a tire while driving down the road.
ERPNext is installed local and all calls are made locals. How can I configure nginx as local?
When using install script, it created automatic several things. It installed Python listening on port 8000, Redis Server listening on port 11000, on port 12000 and on port 13000.
I configured manually Nginx to listen on port 8020. And here is the trick. I set Apache to proxy calls from port 80 to port 8020.
All above works, because when I load http://www.site.com, ERPNext wizard appears (after I log in successfully using Administrator account). I can fill all information each wizard page requested. I can even upload the pictures (of mine and the brand logo) and select domains. When I complete the wizard and presses the last button, it runs several tasks but when it runs the task of setting default values, it throws a 502 Bad Gateway in Chrome, but in NGINX log, the error I have already shown.
By using Firefox, the error shown is the same.
Finally, the https is only for Apache. Locally, it uses only http.
I am playing now with timeouts,because the error is shown 2 min after the POST request… I am wondering what timeout value should I modify.
By seeing -t 120 parameter, I guessed that is the timeout.
I have finally changed supervisor.conf file to define 1200 as the timeout.
That way, process was 30 minutes processing… at last, “Finishing” message appears and get stuck there forever.
I interrupted the process and started again. At this time, wizard started again, but after I entered my information, a message with “Starting Frappe” was shown and got stuck for ever.
I tried to look at the root cause of that issue as well, but found that it was ( Maybe ? ) a socketio issue. I am not real sure.
It would only appear when running bench on localhost, and would be resolved by one of two ways.
Reload the webpage when it fails at the end, and just go through the setup process again. This time it won’t fail.
If in case that does not do the trick, I’ve found running
bench --site sitename migrate
to do the trick. It reads all json files and rebuilds the db, and syncs the help. Plus indexes the global search. But nothing to with socketio. Why this solves the issue, I haven’t figured out.
Nginx is a fully-functioning reverse proxy on its own- why do you need Apache to proxy calls it? I’m going to bet that somewhere in the nginx-Apache configuration is where you’re hitting walls during setup.
Since all of that is running locally amongst itself, you just connect to the python port (8000) via a web browser, and any other quick connections to you just kind of happen unseen in the background (primarily socketio port 9000 connections for file transfer).
Once you make it a live (web-hosted) site- whether just for local intranet or full, public access; basically when you configure your hostname- then the picture becomes:
I’m not sure how you are configuring the whole… apache and nginx thing… but clearly, once you tell it to run on during the initial, browser-based setup, it’s turning nginx on for ‘live’ site mode, kicking everything behind nginx and rerouting port 8000, along with everything else not 80/443, through nginx :: 80.
You end up getting a 502 at this point because Apache is routing traffic from 80 (you) :: 8020 (nginx)… which, after being told to run in ‘live’-site mode, is now blocked. Try this- I’m not sure what you’re using apache for, but take it out of the equation for now.
Just… make it as simple and straight forward as possible just to get past the web-based initial setup. THEN, you can start poking, playing, and rewriting config files because you’ll have a baseline to go back to.
As I said in the first post, I recommend either setting up for local OR ‘live’ via command line (when the only port used is 22… or none if you are legit physically local) and then sticking to that setup through the initial web-based admin configuration. If you are wanting to set up for a ‘live’ site at an address- even for local intranet use and not public use- set up the hostname configurations/nginx setup/multi_tenant_mode PRIOR to accessing the web-based admin setup.
By the way- multi_tenant_mode is what allows you to set up non-standard ports like 8020; search for ‘multi_tenant_mode’ or ‘multi tenant’ on here for several guides.
The important bit, though-
‘local’-access based site :: like 4-5 ports, the main ones being 8000,9000
‘live’-access based site :: 80/443, with nginx serving as gateway/proxy to coordinate everything
IF you insist on configuring ‘live’-access via ‘local’-ports, you HAVE to make sure that the ‘live’-access ports are opened, configured, and redirecting properly in order to maintain a connection when the switch goes into effect. But again. configure access via cli-not the web browser. you’re just asking for issues doing it that way. and with the whole apache thing. Now you’re not just trying to change a tire while driving- you’re trying to do it with a ratchet turning a tire iron.
In the server I have Apache running serving other sites (of course, using port 80). Nginx is used only for ERPNext. That is why I need to proxy it from Apache (I want ERPNext to be accessed without the port).
I am not sure if you have read other posts by me. I told that the 502 error was because connection is suddenly interrupted when calling port 8000, and it was due a time out of 2 minutes. I don’t know why the system lasts too much to configure, but the error I was receiving was only due to that timeout. This has nothing to do with the Apache and Nginx themselves.
Now the question should be, is it normal to last too much in setting up ERP next?
Someone has suggest me to do a “migrate”, but I am not sure if this will solve it.
When you connect ‘locally’ on port 8000, then select a domain VIA WEB-BASED SETUP, the system setup routine switches from ‘local’ operation (port 8000) over to ‘live-site’/domain-setup nginx-proxied port 80. When this occurs, your apache proxy-- still pointing at 8000 (or whatever custom port you are using)-- loses connection since ERPnext is no longer using that port- it’s trying to use port 80, but port 80 is already being used by Apache for your other sites.
In a normal domain setup, the WEB-BASED SETUP might work fine, but you have Apache set up to proxy to custom ‘local’-use access ports and then proceed to tell ERPNext to configure for completely different domain/‘live’-use ports.
The system isn’t taking that long to configure. It’s doing the first couple of things on the list (which may give the appearance of setup progressing normally), then it’s getting to your domain selection where it proceeds to turn off port 8000 and turn on port 80. Hell, it may even be successfully finishing the setup process, but you get a 502/port 8000 timeout because the system has closed port 8000 and switched over to port 80 per default ‘domain’/‘live’-site settings and so never get to see it.
Here’s the standard way to setup a ‘live’ site with port-based multitenancy is:
From terminal on either your current install or a fresh install:
bench update
bench use {site}
bench set-config hostname {domain name}
bench set-config host_name {domain name}
bench config dns_multitenant off
**bench config use-nginx-port {site- as in the name of your site's folder in bench/sites} {port}**
bench setup nginx
sudo service nginx reload
sudo bench restart
But… that won’t really work for you since you’re not setting up multitenancy of erpnext sites on the same server being proxied to via nginx- you’re trying to to setup multitenancy of erpnext and other existing sites that are being proxied to via Apache. So, really it’s the same thing, just applied to Apache…
For ERPNext, from the server terminal on your current or a fresh install, run from the frappe-bench directory:
bench update
bench config dns_multitenant on
bench new-site {site_name} **OR** bench use {site_name}
bench set-config hostname {domain- ie, 'http://{site_name}'}
bench set-confg host_name {domain- ie, 'http://{site_name}'} **I know it's redundant, and honestly one of them probably isn't needed, but I do it that way because everything works when it has both..
bench setup nginx
sudo service nginx reload
bench use {site}
At this point, your installation should be live on port 80, which, of course, will be inaccessible… until you setup multitenancy in Apache to serve ERPNext. I honestly don’t know all that much about Apache, but assuming similarity to nginx/traefik/proxy servers in general, you should likely be able to do some form of dns-based multitenancy to route {erp site}:80 traffic to {erp site}:80 while still routing {website}:80 to {website}:80. As far as I can recall, using port-based multitenancy (as you seem be going for) would always require the port to be specified, which you said you didn’t want to have to do.
The key points, though, are:
domain/dns/port configurations like this need to be done through command line/port 22 SSH, not the web-based interface.
Ultimately, you should be aiming at a normal, no-special-config ERPNext installation that is proxied by your special-config Apache, which is providing the multi-tenancy proxy since it is the bit that is web-facing.
you will not believe it. I have run wizard again, but before, I have changed some mysql configuration as shown here and changed proxies timeouts as shown here . Then, wizard did not take too long and finally I could load ERPNext with all domains! I hope everything have been installed correctly.