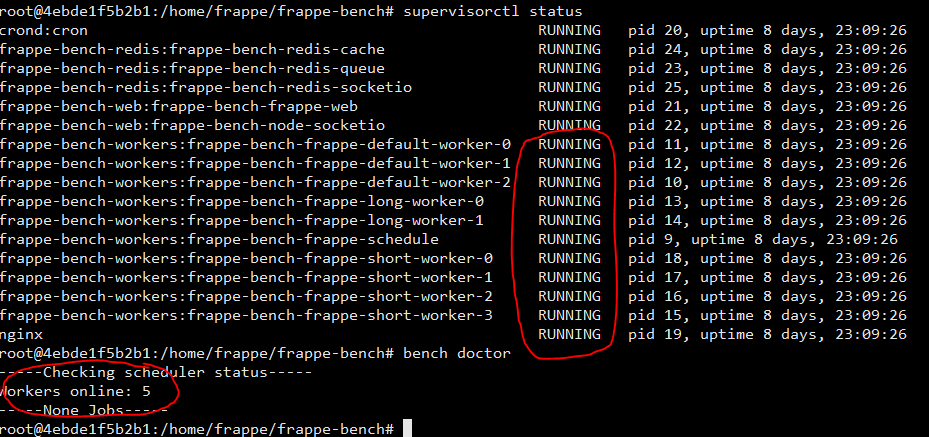
I am running an ERPNext instance at large scale for several months. However, there is problem with worker queue to run automated work. It’s pending a lot of tasks which I need to run bench worker manually. I modified to 9 workers but the same situation.
Moreover, the different between running worker by bench doctor and supervisorctl status
You need to do a reread for the worker processes after you edit the supervisor.conf - you should also check all your log files. I found quite often if I left a process alone even after the timeout, that it would finish in the background some time later (as much as 20mins), but if you close the screen, or click the OK, it seems to terminate.
I would look at the node-socketio.log and see if there’s anything there. In my case it was searching for another IP address (see this post) but I am yet to solve it
For reread the supervisor.cfg, I do it for sure to have the 9 workers as above. When I check the log of worker error, mostly is error of invalid argument from os.rename of logging library.
Check for the job queue in redis, I see a huge number of update_gravatar and aws job. I though they make this pending happend but when I run bench worker in terminal, I made these 500 tasks done in 2 minutues. Haven’t dig down into these function, but I will disable these standard job of erpnext. Node-socket.io is often find a way to connect to erpnext hub and some other services but it not impact to the worker.